
 Takedown notices are a vital tool for copyright holders who want to make sure that infringing copies of their work are not widely distributed.
Takedown notices are a vital tool for copyright holders who want to make sure that infringing copies of their work are not widely distributed.
Every week millions of these requests are sent to hosting platforms, as well as third-party services, such as search engines.
Quite a few of the major players, including Twitter, Google, and Bing, publish these requests online. However, due to the massive volume, it’s hard for casual observers to spot any trends in the data.
Researchers from Queen Mary University of London and Boston University aim to add some context with an elaborate study covering a broad database of takedown requests. Their results are now bundled in a paper titled: “Who Watches the Watchmen: Exploring Complaints on the Web.”
The research covers all takedown requests that were made available through the Lumen Database in 2017. The majority of these were sent to Google, with Bing, Twitter, and Periscope as runners-up. In total, more than one billion reported URLs were analyzed.
Most takedown requests or ‘web complaints’ were copyright-related, 98.6% to be precise. This means that other notices, such as defamation reports, court orders, and Government requests, make up a tiny minority.
The researchers report that the complaints were submitted by 38,523 unique senders, covering 1.05 billion URLs. While that’s a massive number, most reported links are filed by a very small group of senders.
“We find that the distribution of notices is highly skewed towards a few extremely active senders. The top 10% of notice senders report over 1 billion URLs, in stark contrast to just 550K by the bottom 90%,” the researchers write.
Not surprisingly, the list of top senders is entirely made up of anti-piracy groups and trade organizations. In 2017, the top senders were Rivendell, Aiplex, and the UK music group BPI.
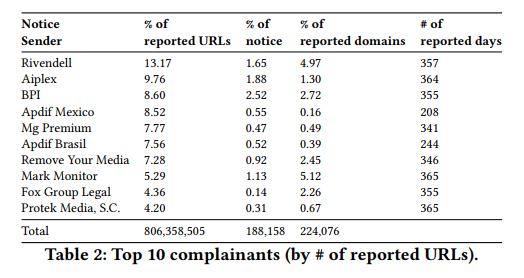
On the domain side, the results are skewed as well. The top 1% of all reported domain names were targeted in 63% of all complaints. In other words, a small number of sites are responsible for the vast majority of all takedown notices.
These and other figures provide more insight into the various takedown characteristics. What we were most surprised about, however, are the researchers’ findings regarding the availability of the reported domain names.
The researchers carried out periodic checks on the domains and URLs to verify if the websites are still active. This revealed that a few weeks after the first takedown notices were filed, 22% of the reported domains were inactive, returning an NXDOMAIN response.
“Many domain names are soon taken offline and 22% of the URLs are inaccessible within just 4 weeks of us observing the complaints. Hence, it is clear that we shed light on a highly dynamic environment from the perspective of domain operators too,” the article reads.
With a total dataset of more than a billion domain names, this suggests that hundreds or thousands of sites simply disappeared. Whether the takedown requests have anything to do with this is unclear though, as many site owners may not even be aware of them.
The disappearing domain names mostly use more exotic TLDs, with .LOL being the most popular, followed by .LINK, .BID, .SPACE, and .WIN. The vast majority of these (97%) have an Alexa rank lower than one million, which means that they only have a few visitors per day.
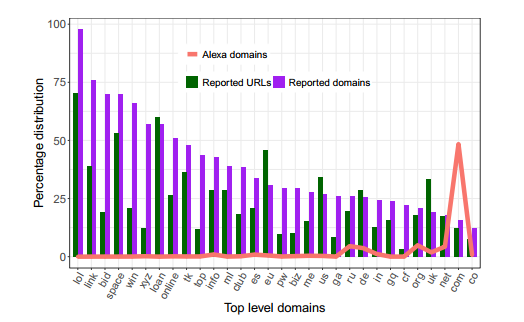
It’s not clear why these domains disappear and the authors of the article stress that follow-up research is required to find out more. It would not be a surprise, however, if many of these are related to spam or scams that rely on temporary search engine traffic.
Finally, the article also observed worrying activity carried out by copyright holders. For example, some use seemingly fabricated URLs, as we have highlighted in the past, while others send hundreds of duplicate notices.
All in all the research should help to provide a better understanding of how takedown requests impact various stakeholders. This type of transparency is essential to improve procedures for the senders, but also to prevent abuse.
“Transparency is critical and, as a society, it is important to know how and why information is filtered. This is particularly the case as we have found that these mechanisms might not be always used wisely,” the researchers conclude.







